

紙の郷土史をAIで読めるMarkdownに変換した実践記録
紙の郷土史をスキャンしたPDFから、NotebookLMで扱えるMarkdownを作るまでの実践記録です。 PaddleOCRで横書き本を処理したあと、縦書き日本語書籍でつまずき、最終的にNDLOCR-Liteへ乗り換えました。
1. ゴールは「NotebookLMに読み込ませられるMarkdown」
今回の目的は、紙の郷土史を電子化し、NotebookLMのようなAIツールで扱いやすい形にすることだった。
単にPDFにするだけではなく、検索できるテキストデータにする。さらに、あとからNotebookLMに読み込ませやすいように、Markdown形式で整理する。
最終的な出力イメージは、次のようなシンプルな構造にした。
# 書名
本文の段落…
---
<!-- page 12 -->
次のページの本文…ここで大事にしたのは、凝りすぎないことだった。
見出しを自動で推定して ## や ### を付けることも考えられる。しかし、300ページから600ページ規模の書籍で見出しを誤検出すると、かえって本文構造が壊れてしまう。
NotebookLMで使うことを考えれば、まず重要なのは次の3点だ。
- 本文が読めること
- ページの区切りがわかること
- あとから検索・引用しやすいこと
そのため、今回は見出しの自動推定までは行わず、ページ単位で区切ったMarkdownを作る方針にした。
2. 横書き本はPaddleOCRでうまくいった
最初に対象にしたのは、横書きの郷土史だった。ページ数は638ページほどある。
当初は、Claude Codeに相談しながら PaddleOCR 3.x を使うことにした。理由はシンプルだ。
- 日本語に対応している
- 情報が多い
- GPU環境で動かせる
実際に処理してみると、横書き本についてはかなり実用的だった。638ページの本を、GPU環境で17分49秒ほどで処理できた。1ページあたり約1.7秒である。
もちろん、OCRなので完璧ではない。
固有名詞の誤認識、数字の読み違い、改行の乱れ、不要なスペースの混入などはある。それでも、紙の本が検索可能なテキストになるだけで、活用の幅は大きく広がる。
この時点では、「これはかなり使えるのではないか」と感じていた。
3. 縦書き日本語書籍でPaddleOCRが崩れた
問題は、次に扱った縦書きの日本語書籍だった。
横書きではそれなりにうまくいっていたPaddleOCRが、縦書きになると一気に不安定になった。
実際に起きた問題は、次のようなものだ。
| 症状 | 内容 |
|---|---|
| 読み順の崩れ | 段落が混ざり、通読しにくくなる |
| 促音の脱落 | 「行った」が「行て」のようになる |
| 長音の脱落 | 「シームレス」が「シムレス」のようになる |
| 句読点の消失 | 「、」「。」が大きく抜ける |
| 鉤括弧の消失 | 引用部分が本文に溶け込む |
| 右端列の欠落 | 縦書きページの右端の本文が読まれない |
PaddleOCR自体が悪いというより、今回の対象がかなり難しかったのだと思う。
郷土史のような縦書き日本語書籍には、次のような特徴がある。
- 縦組み
- 段組み
- ルビ
- 注記
- 旧字体
- スキャン品質のばらつき
- ページ端の影やゆがみ
人間にとっては自然に読める紙面でも、OCRにとってはかなり厄介な対象になるようだ。
特に、本文の一部が丸ごと欠落してしまうと、後処理ではどうにもならない。そこで、OCRエンジンそのものを見直すことにした。
4. NDLOCR-Liteに乗り換えた
最終的に使うことにしたのが、国立国会図書館が公開している NDLOCR-Lite だった。
NDLOCR-Liteは、国立国会図書館のデジタル化資料をOCRするために作られている。つまり、そもそもの対象が「書籍」に近い。
今回のような縦書き日本語の郷土史には、PaddleOCRよりも相性がよかったのかもしれない。
同じページで比較すると、PaddleOCRで崩れていた部分がかなり改善された。
| 指標 | PaddleOCR | NDLOCR-Lite |
|---|---|---|
| 本文のまとまり | 細切れになりやすい | 段落に近い形で出る |
| 右端列の本文 | 欠落することがあった | 読み取れた |
| 促音「っ」 | 落ちやすい | 復元された |
| 句読点 | 消えやすい | かなり残った |
| 320ページの処理時間 | GPU利用でも時間がかかった | CPUのみで5分47秒 |
特に大きかったのは、CPUだけで実用的な速度が出たことだった。
320ページほどの縦書き書籍を、5分台でテキスト化できた。これは個人で郷土史や地域資料を扱う用途としては、かなり現実的な速度だと思う。(ただし、これに関してはどのような条件によりこの結果が出たのかは検証していない。その点はご容赦いただきたい。)
もちろん、NDLOCR-Liteでも完全ではない。それでも、縦書き日本語書籍をMarkdown化するという目的に対しては、かなり有力な選択肢だった。
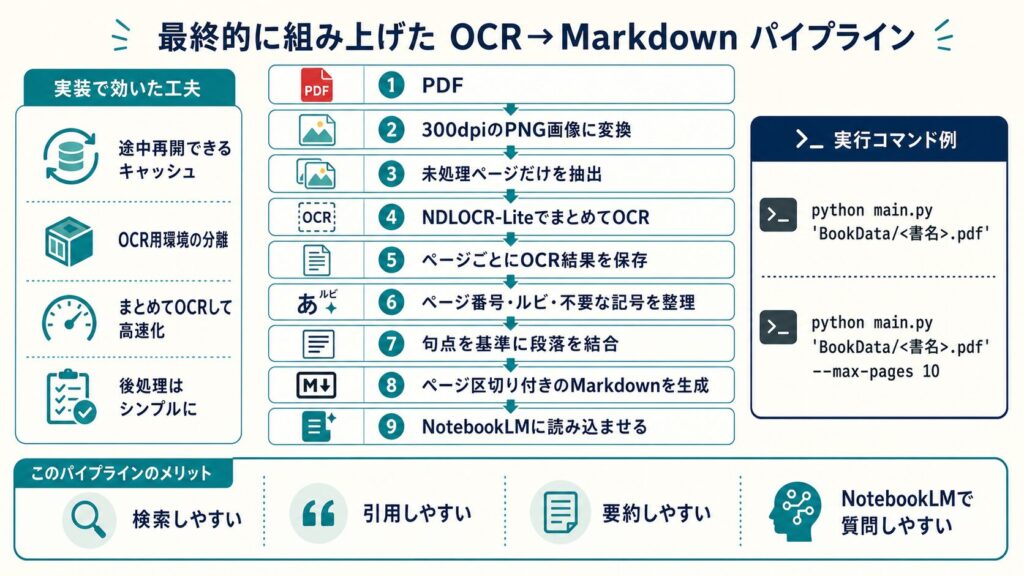
5. 実装で効果的だった工夫
OCRエンジンを変えただけで、すべてが解決したわけではない。実際に使えるパイプラインにするには、いくつか工夫が必要だった。
途中再開できるようにする
まず大事だったのは、途中再開できることだ。
数百ページのOCR処理を一気に走らせる場合、途中で失敗することは十分ありえる。そのたびに最初からやり直すのは現実的ではない。
そこで、処理結果をページ単位で保存するようにした。
- PDFから変換したページ画像
- OCR結果のJSON
- 最終的なMarkdown
このように段階ごとに保存しておくと、途中で止まっても未処理ページから再開できる。また、Markdownの整形方法だけを変えたい場合は、OCRを再実行せずに済む。
これは、実際にかなり効いた。
OCR用の環境を分ける
次に、Python環境を分けた。
NDLOCR-Liteは、使うライブラリのバージョン指定がある。本体の処理で使うライブラリと混ざると、依存関係の衝突が起きる可能性がある。
そこで、処理本体用の環境と、NDLOCR-Lite用の環境を分けた。
.venv/ 本体処理用
.venv-ndlocr/ NDLOCR-Lite用このように分けておくと、あとからNDLOCR-Lite側を更新しても、本体側への影響を抑えやすい。
個人開発ではつい環境を一つにまとめたくなるが、外部ツールを組み込む場合は、環境を分けた方が安定することがある。
ページごとではなく、まとめてOCRする
NDLOCR-Liteは、起動時にモデルを読み込むため、最初に少し時間がかかる。
もし1ページごとに起動していたら、その起動時間がページ数分だけ積み重なってしまう。320ページなら、初期化だけでかなりの時間を無駄にする。
そこで、未処理ページをまとめて一度にOCRへ渡すようにした。
これにより、モデル読み込みのコストを1回で済ませられる。数百ページの本を処理する場合、この差はかなり大きい。
段落結合はシンプルにした
OCR結果をそのままMarkdownにすると、行が細かく分かれて読みにくい。そのため、行を段落として結合する処理を入れた。
今回は、基本的に 句点で文が終わるまでを1段落として結合する というシンプルな方法にした。
PaddleOCRを使っていたときは、行の長さや位置を使った複雑な調整も考えた。しかし、NDLOCR-Liteに変えてからは、OCR結果そのものがかなり良くなったため、後処理は単純で済んだ。
この点はかなり重要だと思う。
OCRの精度が低い状態で後処理を頑張るより、対象に合ったOCRエンジンを選んだ方が、全体の処理はシンプルになる。
6. それでも残った弱点
NDLOCR-Liteに変えても、すべてが完璧になったわけではない。
実際には、いくつか弱点も残った。
長い縦書き本文で一部乱れることがある
縦書きの長い本文ページでは、ごくまれにフレーズの繰り返しや一部スキップが起きることがあった。
頻度としては高くない。NotebookLMで質疑応答に使う程度であれば、致命的ではないと感じた。
ただし、正確な翻刻や校正済みテキストとして使うなら、目視確認や修正は必要になる。
縦中横の認識は資料によって注意が必要
NDLOCR-Liteには、縦書き中の数字などを扱うためのオプションがある。しかし、今回の資料では、その機能を有効にすると、かえって本文に不要な句読点が入ることがあった。
便利そうな機能でも、自分の資料に合うとは限らない。
結局のところ、OCRでは 代表的なページを数ページ選んで実測すること が一番大事だと感じた。
7. 最終的なパイプライン
最終的な流れは、次のようになった。
PDF
↓
300dpiのPNG画像に変換
↓
未処理ページだけを抽出
↓
NDLOCR-LiteでまとめてOCR
↓
ページごとにOCR結果を保存
↓
ページ番号・ルビ・不要な記号を整理
↓
句点を基準に段落を結合
↓
ページ区切り付きのMarkdownを生成
↓
NotebookLMに読み込ませる実行自体は、最終的に1コマンドでできるようにした。
python main.py 'BookData/<書名>.pdf'また、最初から全ページを処理するのではなく、最初の10ページだけ試すこともできるようにした。
python main.py 'BookData/<書名>.pdf' --max-pages 10これはかなり大事だった。
OCRは、実際に数ページ試してみないと品質がわからない。本番処理の前に10ページ程度で確認するだけで、無駄な処理や失敗をかなり減らせる。
8. NotebookLMで何が変わるか
Markdown化した郷土史をNotebookLMに読み込ませると、紙の本のままでは難しかったことができるようになる。
たとえば、次のような使い方ができる。
- 本文を検索できる
- 特定の人物名や地名を探せる
- 事業の経緯を要約できる
- 関係者や出来事の流れを質問できる
- 引用元を確認しながら内容を読むことができる
紙の本は、じっくり読むにはとてもよい。しかし、調べものや資料づくりに使う場合は、検索性が大きな壁になる。
Markdown化してNotebookLMに読み込ませることで、郷土史は「読む資料」から「問いかけられる資料」に変わる。
これは、地域資料の活用にとってかなり大きな変化だと思う。
地域に残された郷土史、記念誌、事業史、団体史のような資料は、紙のままだとどうしても限られた人にしか届かない。しかし、AIで扱える形にしておけば、記事、教材、スライド、講話資料、地域学習などに展開しやすくなる。
9. 今回やってみてわかったこと
横書きの資料ではPaddleOCRでも十分使えた。しかし、縦書き日本語書籍では大きく崩れた。
一方で、NDLOCR-Liteは、縦書きの書籍に対してもかなり相性がよかった。
つまり、OCRでは次の視点が重要になる。
- 資料は横書きか縦書きか
- 書籍か帳票か、新聞か、手書きか
- 段組みやルビがあるか
- スキャン品質はどの程度か
- 最終的に何に使うのか
今回の目的は、完全な翻刻ではなく、NotebookLMで参照できるMarkdownを作ることだった。そのため、多少の誤認識が残っても、検索や要約、質疑応答に使える品質であれば実用になる。
逆に、歴史資料として公開する正式テキストを作るなら、もっと厳密な校正が必要になる。
ここは、目的によって割り切る必要があると思っている。
まとめ
今回、紙の郷土史をスキャンしたPDFから、NotebookLMで扱えるMarkdownを作るパイプラインを作った。
最初はPaddleOCRを使い、横書き本では十分実用的な結果が得られた。しかし、縦書き日本語書籍では読み順の崩れ、促音や句読点の脱落、本文列の欠落などが目立った。
そこでNDLOCR-Liteに乗り換えたところ、縦書き本文の読み取り品質が大きく改善した。CPUだけでも320ページを5分台で処理でき、個人でも十分扱える速度だった。
実装面では、途中再開できるキャッシュ、OCR用環境の分離、まとめて処理する方式、句点を基準にした段落結合が効果的だった。
もちろん、完全ではない。長い縦書き本文では一部の繰り返しやスキップが起きることもある。正式な翻刻や公開資料にするなら、目視確認と校正は必要になる。
それでも、紙の郷土史をAIで扱える知識資源に変えるという目的には、かなり現実的な方法だと感じた。
紙の本には紙の本の価値がある。一方で、検索できるテキストにすることで、その資料は新しい使われ方を得る。
郷土史を眠らせず、次の世代に伝えるための入口として、OCRとMarkdown化、そしてNotebookLMのようなAIツールの組み合わせは十分に試す価値があるだろう。
