

縦書き日本語の書籍PDFを NotebookLM 用 Markdown に変換するパイプラインを作った
— PaddleOCR から NDLOCR-Lite への乗り換えと、Claude Code との二人三脚開発
紙の郷土史をAIで読める形にする。地域の記憶をMarkdown化するまでの試行錯誤を、実践記録としてまとめておきたい。関連記事は以下のリンク先に掲載する。
はじめに
毎月原稿を書いている雑誌の取材で、ある団体を訪ねたときのことだ。その団体から、数年前に作成したという郷土史を一冊いただいた。
内容は、農業用水に関する地域開発史。かつて慢性的な水不足に苦しんでいた地域を救うために立ち上がった人々の歩みが、丁寧に綴られていた。
取材後、帰宅してからその郷土史を読み進めていくと、その事業が決して一筋縄ではいかなかったことがわかる。
地域を救うための事業でありながら、救済の対象であるはずの地元農家の一部から反対同盟が生まれる。開発のための負担金が増えることを不安したことが反対の理由だったとのこと。関係者の調整、財源の確保、技術的な課題、地域内の合意形成、そして、国との交渉。そこには、今の私たちが想像する以上の困難があったようだ。
それでも事業は実現し、結果として地域の水不足は大きく改善された。そして今では、この地域がかつて慢性的な水不足に悩まされていたことを知る人は、わずかになっている。
取材のなかでも、「この歴史を地域に住む人たちに知ってほしい」という思いを強く感じた。
取材後に郷土史を読み終えたとき、私自身も同じ考えに至った。
これは、現在この地域に住む人たちが知っておくべき、先人たちの歴史だ。
しかし同時に、現在の紙の本のままでは、届く人が限られてしまうとも感じた。
紙の本の価値と、紙のままでは届きにくい現実
もちろん、紙の本には紙の本の良さがある。
手に取ったときの重み。ページをめくる感覚。資料としての存在感。地域の記録として、きちんと形になっていること自体に大きな価値がある。
一方で、紙の本のままでは、どうしても次のような制約がある。
- 本の存在を知っている人しか読まない
- 保管場所に行かなければ手に取れない
- 本文を検索できない
- 必要な部分を抜き出すのが難しい
せっかく地域にとって重要な記録が残されているのに、そのまま眠ってしまうのはもったいない。
そこで考えたのが、この郷土史を電子化し、さらにMarkdown形式のテキストファイルにすることだった。
PDFにするだけではなく、テキストとして扱える形にする。そうすれば、検索できる。引用しやすくなる。要約もできる。NotebookLMのようなRAGツールに読み込ませることもできる。
将来的には、地域の歴史をわかりやすく伝える資料やスライド、記事、教材づくりにも活用できるかもしれない。
紙の郷土史を、AI時代に扱いやすい知識資源へ変換する。
そんな実験として、今回の取り組みを始めた。
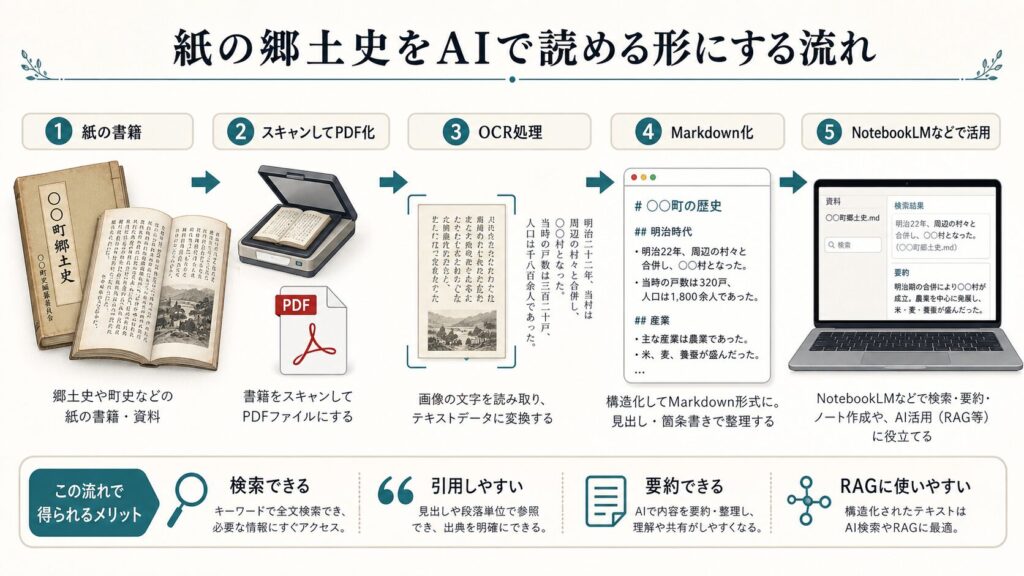
まずはスキャン代行でPDF化する
最初に行ったのは、紙の本をデジタルデータにすることだった。
自分でスキャンする方法もあるが、今回はスキャン代行サービスに依頼した。書籍を画像PDFに変換してもらい、そのPDFをもとにOCR処理を進めることにした。
その後は、Claude Codeに相談しながら作業を進めた。
目的は、画像PDFから文字を読み取り、最終的にMarkdown形式のテキストファイルへ変換すること。単にOCRにかけて終わりではなく、後からAIに読み込ませやすい構造に整えることを目指した。
最初に扱った郷土史は、横書きだったこともあり、OCR処理は拍子抜けするほど簡単だった。
Claude Codeが勧めてくれたとおりPaddleOCRをインストールしてもらい、PDFを画像ファイルに変換してからOCR処理を実行する。多少の文字認識ミスはあるものの、AIに読み込ませて活用する前提であれば、実用に足るのではないかと感じる出来だった。
固有名詞の誤認識、数字の読み違い、改行の乱れ、不要なスペースの混入などはある。それでも、紙の本が検索可能なテキストになるだけで、活用の幅は一気に広がる。
これはいけるかもしれない。
そう思った。
縦書き日本語書籍という壁
その後、データを補強するために、別の郷土史も電子化することに。
ところが、こちらは縦書きの日本語書籍だった。これが思っていた以上に難しかった。
横書きの資料ではそれなりにうまくいっていたOCR処理が、縦書きになると一気に崩れる。
- 文字の順番が乱れる
- 行のつながりがおかしくなる
- 段組みやルビ、注記が混ざる
- ページ番号や見出しが本文に紛れ込む
日本語の縦書き書籍は、人間にとっては自然に読める。しかし、OCRにとってはなかなか厄介な対象らしい。
いくつかの方法を試した結果、最終的に行き着いたのが、国立国会図書館が公開している NDLOCR-Lite だった。
これがかなり良かった。
CPUだけの環境でも、320ページほどある縦書きの書籍を5分台でテキスト化できた。しかも、縦書き日本語に対する認識も比較的安定している。
もちろん、こちらも完全ではない。だが、縦書きの郷土史を短時間でテキスト化できるという点では、非常に実用的だった。
Claude Codeを相棒にする感覚
今回の作業で面白かったのは、Claude CodeがOCRソフトと生成したプログラムを連携させて書籍を電子化したことだけではない。
むしろ、Claude Codeを相棒にしながら、処理の流れやフォルダ構成、スクリプトの設計を少しずつ固めていき、目的を達成できたことが大きかった。
たとえば、次のような作業を一つひとつ相談しながら進めた。
- PDFを画像に変換する
- OCRエンジンにかける
- ページごとのテキストを保存する
- Markdownとして結合する
- 見出しやページ番号をどう扱うか考える
- 後から修正しやすいレポジトリ構成にする
自分ひとりで最初から完璧な設計を考えるのではなく、まずは目的を確認する。そして、そのための要件を壁打ちしながら固めていく。
それから、動くものを小さく作る。うまくいかなければ原因を確認する。処理を分ける。ファイル名を整理する。別のOCRエンジンを試す。
その行きつ戻りつの過程そのものが、今回の記録の中心でもある。
AIを使うというと、どうしても「ボタン一発で全部やってくれる」ようなイメージを持ちがちだ。しかし実際には、目的を決め、素材を整え、出力を確認し、必要に応じて修正する人間側の判断が欠かせない。
AIは魔法の杖というより、かなり優秀な作業相棒に近い。
今回の作業では、その感覚を強く感じた。
この関連記事で書くこと
この記事では、紙の郷土史をスキャンし、OCR処理を行い、Markdown形式のテキストデータにしていくまでの試行錯誤を記録する。
特に、次のような人を想定している。
生成AIの活用に関心がある人
NotebookLMのようなRAGツールに、自分の手元にある資料を読み込ませたい人。紙の本やPDFをAIで扱いやすくするには、どのような前処理が必要なのか知りたい人。Claude Codeのようなコーディングエージェントと一緒に、実際の作業をどう進めるのか興味がある人。
OCR処理に関心がある人
日本語書籍、特に縦書きの本をOCRにかけると何が壊れるのか。PaddleOCRとNDLOCR-Liteでは何が違うのか。画像PDFからテキスト化する際に、どこでつまずくのか。そうした実装上のハマりどころを知りたい人。
この記事は、完成されたノウハウ集というより、試行錯誤の記録である。
うまくいったこともあれば、うまくいかなかったこともある。最初から最適解にたどり着いたわけではない。むしろ、あれこれ試しながら、少しずつ実用に近づけていった。
その過程を、成果物のレポジトリ構成や内部設計にも触れながら書いていきたい。
